0. 들어가며
지난 한 주간 SQL 튜닝 교육을 받으러 다녀왔는데요, DBA가 아닌 이상 알기 어려운 지식들을 많이 배울 수 있었던 기회였습니다. 이번 포스팅에서는 그 중 실행계획과 옵티마이저에 대해 정리해보고자 합니다.
목차
1. SQL 튜닝의 필요성과 절차
2. SQL 처리단계
3. 실행계획과 옵티마이저
4. 쿼리 힌트
5. 마무리
1. SQL 튜닝의 필요성과 절차
1-1. SQL 튜닝이란?
튜닝이란 시스템이 최적의 성능을 발휘할 수 있도록 시스템을 유지·개선 하는 일을 의미합니다. 우리가 구축한 시스템이 최적의 성능을 발휘하기 위해선 최소한의 자원으로 최대한의 일을 할 수 있어야 할텐데요, 이런 의미에서 SQL 튜닝은 가장 적은 작업량으로 사용자가 원하는 결과를 얻어낼 수 있도록 SQL 쿼리를 작성하고, 기존 쿼리를 개선하는 작업이라고 할 수 있습니다.
1-2. SQL 튜닝의 필요성
데이터베이스 접근의 효율성, 다시 말해 효율적인 DB I/O는 우리가 사용하는 대부분의 웹어플리케이션의 성능에 가장 큰 영향을 미치는 요인 중 하나입니다. DB I/O는 단순한 CPU 부하나 메모리 접근에 비해 매우 많은 시간이 소요되는 작업이기 때문인데요, 따라서 비효율적인 DB I/O를 개선하는 것이 웹어플리케이션 성능 개선의 핵심이라고 할 수 있습니다.
1-3. SQL 튜닝 절차
기본적으로 SQL 튜닝은 [대상선정 - SQL 수행 및 결과 확인 - 튜닝 포인트 확인 - SQL 튜닝 - 검증 및 적용] 의 단계로 이뤄지는데요, 이번에 제가 들었던 교육은 이 단계 중 'SQL 튜닝' 단계에서 살펴봐야할 기본적인 요소들을 다뤘고, 앞으로도 이 SQL 튜닝의 기본 요소들에 대해 포스팅을 이어가도록 하겠습니다.
💡 SQL 튜닝의 3가지 접근 방법
1. 부하의 감소 (일반적인 SQL 튜닝)
- 동일한 부하를 효율적인 방법으로 수행
- INDEX 변경/조정, JOIN 조정/변경, ACCESS 변경 등
2. 부하의 조정
- 배치, 리포트 업무와 온라인(OLTP) 업무를 분리
- 어플리케이션, 시간대별 부하 배분
3. 부하의 병렬수행
- 주로 배치 업무에 많이 사용
2. SQL 처리단계
2-1. SQL의 처리과정 : Parse - Bind - Execute - Fetch
우리가 작성하는 SQL 문은 크게 Parse-Bind-Execute-Fetch 의 4가지 단계로 처리됩니다. 가장 먼저 살펴볼 과정은 Parse 단계로 Parse 단계에서는 기본적인 문법과 권한 검사가 이뤄지고, Optimizer 가 실행계획을 생성합니다. 또 많이 들어보셨을 Soft-parse 와 Hard-parse 작업이 진행되기도 합니다. 자세한 내용은 아래와 같습니다.
(1) Parse
- Syntax Check : SQL이 올바르게 작성되었는지 확인
- Search Shared SQL Area : 같은 SQL(p-code*)이 Shared Pool 에 있는지 확인 ➡️ 존재하는 경우 바로 실행(soft-parse)
- Semantics Check : 테이블, 컬럼명 확인 및 권한, 보안사항 등 확인
- Optimizer : Execution plan 결정
- Save Execution Plan : Shared Pool 에 Parse 정보를 저장 ➡️ 실행(hard-parse)
* p-code : 오라클 DB 는 동일한 SQL 문이 있는지를 검사할 때 곧바로 String 비교를 수행하지 않고, 주어진 SQL 문 전체를 ASCII 값으로 변경 후 합계를 계산한 뒤에 그 값이 같은 쿼리만을 대상으로 String 비교를 수행한다. 이 때 SQL문을 ASCII 코드의 합으로 변경한 값을 p-code 라고 한다.
두 번째 단계는 Bind 입니다. Bind 단계는 SQL 문에 Bind 변수가 포함된 경우에만 수행됩니다.
(2) Bind
- SQL 문이 Bind 변수를 포함한 경우 p-code 에 해당 변수값을 지정
- Bind 변수가 포함된 경우만 수행
세 번째 단계는 Execute 입니다. 실행 단계에서는 SELECT 문과 INSERT/UPDATE/DELETE(DML) 문을 실행할 때 조금의 차이가 있는데요, 이 점을 유의해서 기억하면 좋을 것 같습니다.
(3) Execute
- 실행 계획(Plan) 적용
- DML 문의 경우 I/O 작업 수행
💡 SELECT 문 실행
- 원하는 데이터가 저장된 Disk Block 들을 DB Buffer Cache 로 복사
1. Logical Read : DB Buffer Cache 에 원하는 데이터가 존재해서 Disk 접근을 하지 않은 경우
2. Physical Read : Memory 에 원하는 데이터가 없어서 Disk 에서 데이터를 가져오는 경우
- Logical - Physical 은 확률적인 문제이므로 튜닝의 주된 관심사는 아닙니다. 몇개의 데이터 Block 에 접근했는지를 보여주는 CR 이나 Buffers 같은 값을 줄이는 게 튜닝의 주된 관심사라고 할 수 있습니다.
💡 DML 문 실행
1. 변경할 데이터가 위치한 Block 이 DB Buffer Cache 에 있는지 확인하고 없으면 복사
2. Undo Block 을 DB Buffer Cache 에 복사
3. 변경할 Row 에 Lock
4. Redo Log Buffer* 에 작업 내용 기록
5. 변경 전 데이터를 2번에서 복사해온 Undo Block 에 저장
6. DB Block 의 데이터 수정
* Redo Log Buffer 는 롤백 시 사용하지 않고, 시스템 장애 복구 시에만 사용하고, 롤백 시에는 Undo Block 을 사용.
마지막으로 살펴볼 단계는 Fetch 입니다. Fetch 는 SELECT 문에서만 수행되는 단계이며, Fetch 작업을 통해 DB Buffer Cache 데이터 중 사용자가 요청한 column, row 만 사용자에게 전달해줍니다.
(4) Fetch
- DB Buffer Cache 데이터 중 사용자가 요청한 column, row 만 사용자에게 전달
- 어플리케이션에서 페이징 처리 등을 통해 Array size(운반단위)* 를 조정할 수 있음.
* 가령 20,000 건의 데이터가 조회된 경우 Array size 를 10으로 설정하면 어플리케이션 화면에서 빠르게 결과를 볼 수 있지만 DB 접근 횟수는 증가한다. 반면 Array size 를 1000으로 설정하면 어플리케이션 화면에서 결과를 보는 데는 긴 시간이 걸리지만 DB 접근 횟수는 감소한다. 따라서 어플리케이션 개발자는 Batch 작업 시에는 크게, OLTP 서비스 에서는 필요한 page size 에 맞게끔 적절한 Array size를 설정해줘야 한다.
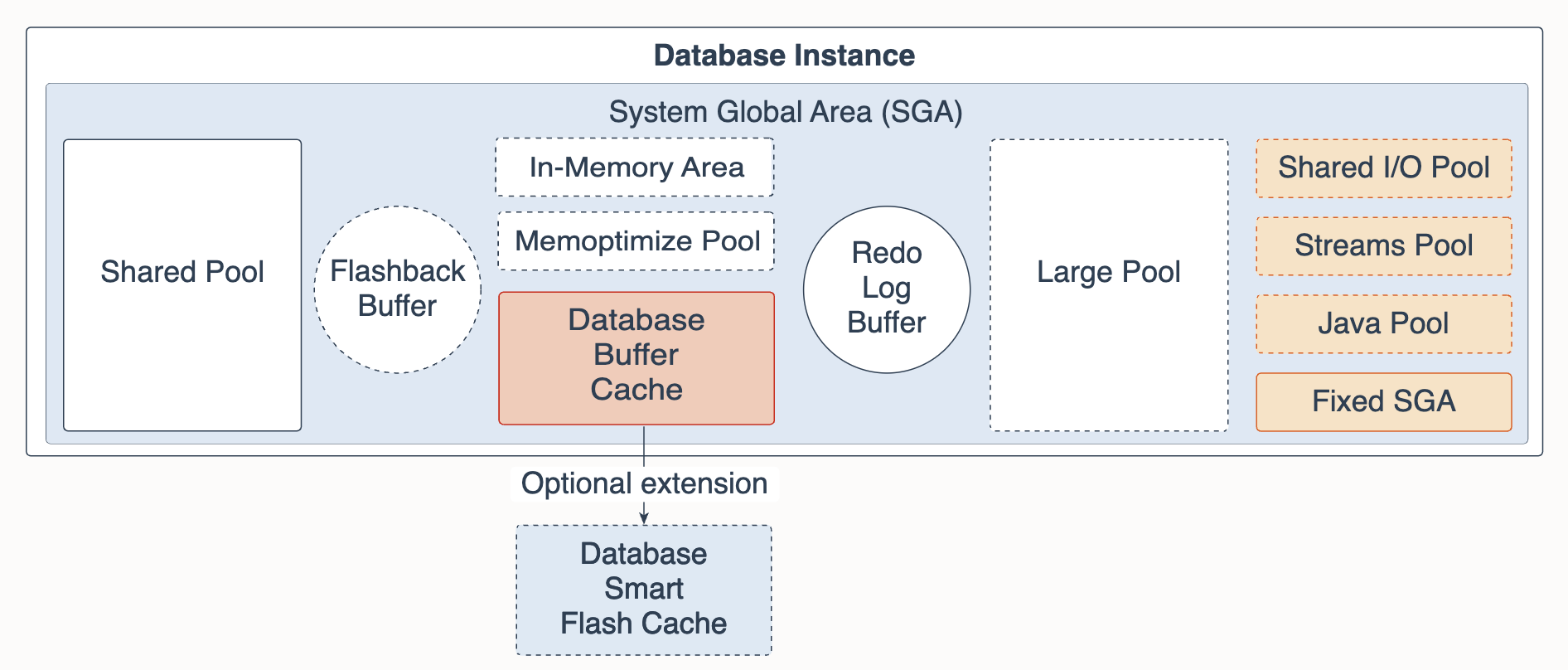
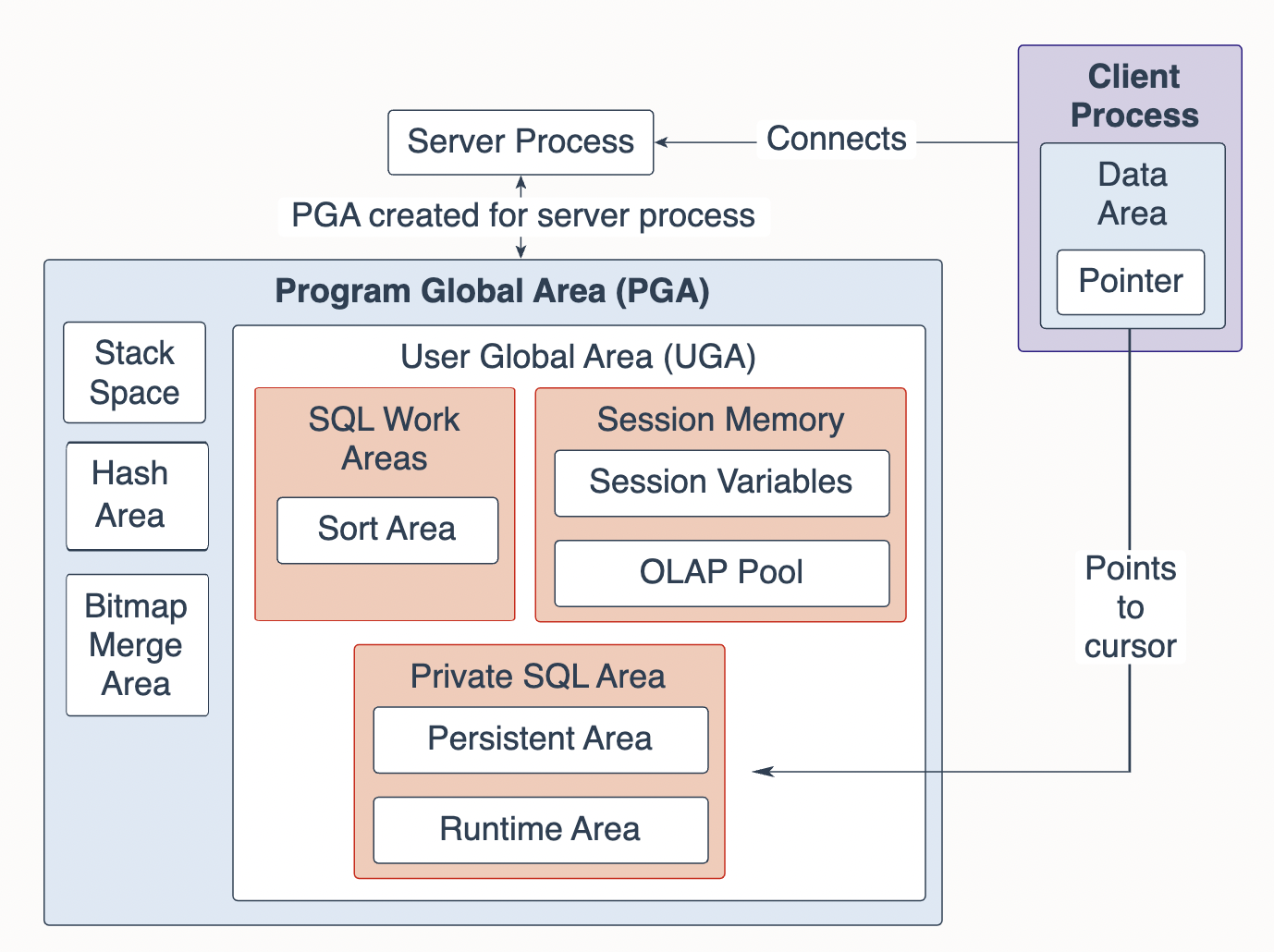
2-2. 오라클의 주요 아키텍쳐(Memory, Data File)
위에서 정리한 내용을 잘 이해하고 실제 SQL 튜닝을 진행하기 위해서는 오라클의 기본적인 아케텍쳐를 어느정도 알고있는 게 좋습니다. 먼저 가장 기본적인 오라클 DB 구조부터 살펴볼텐데요, 오라클의 메모리 영역은 Program Global Areas(PGA) 와 System Global Area(SGA) 크게 두 개 영역으로 구분됩니다.
💡 오라클의 메모리 영역
(1) PGA 영역
클라이언트의 SQL 처리 요청을 받는 서버프로세스가 사용하는 메모리 공간으로 sorting 이나 hash_join 작업 시에 프로세스가 활용
(2) SGA 영역
여러 프로세스가 공유하는 영역으로 parsing 작업이나 데이터를 읽어오기 위한 buffer cache 등에 활용

추가로 각 메모리 영역이 구체적으로 어떻게 구성되어 있는지 살펴볼텐데요, 먼저 SGA 영역을 보면 Parse 단계에서 탐색하는 Shared Pool 이나 Execute 단계에서 Disk 에 있는 데이터를 가져와 적재하는 Database Buffer Cache, 장애 복구 시 활용하는 Redo Log Buffer 등을 확인하실 수 있습니다. 다음으로 PGA 영역에선 Sorting 이나 Join 시에 활용하는 Sort Area, Hash Area 등을 확인하실 수 있는데요, Sorting과 Join에 관련 내용은 이후에 좀 더 자세히 다뤄보도록 하겠습니다.
3. 실행계획과 옵티마이저
3-1. 옵티마이저의 역할과 목표
옵티마이저는 SQL 문장에 의해 접근되는 스키마 객체(테이블 또는 인덱스) 들의 통계를 기반으로, 어떠한 경로로 객체에 접근하는 것이 가장 효율적인지 실행계획을 결정해줍니다. 그리고 이렇게 결정된 실행 계획을 흔히 Execution plan 이라고 부르는데요, 옵티마이저의 목표는 그 역할에서 드러나듯 가장 비용이 적은 실행계획을 찾아내는 것입니다.
3-2. 옵티마이저의 실행계획 결정기준
옵티마이저는 두 가지 방식을 사용해 실행계획(plan)을 결정할 수 있습니다. 첫 째는 규칙기반(RBO) 방식으로, 사전 등록된 우선순위를 기준으로 실행계획을 결정하는 방식인데요, 현재는 잘 쓰이지 않고 있습니다. 다른 하나는 비용기반(CBO) 방식인데요, 사전에 작성된 통계정보를 바탕으로 계산한 Time cost 를 고려해 실행계획을 결정하는 방식으로, 현재 대부분의 시스템에서 주로 쓰이고 있는 방식입니다. 참고로 이 때 비용기반 방식에서 사용하는 통계정보는 늘 실시간으로 관리되지는 않는다는 점을 유의해야 합니다.
3-3. 실행계획 확인 방법
옵티마이저가 작성한 실행계획을 확인하는 방법에는 여러가지가 있지만, 제 기준에서 가장 사용이 쉬웠던 방법은 SQL*PLUS 프로그램의 AUTOTRACE 기능을 활용하는 것이었습니다. 이 기능을 사용하면 CLI 환경에서 손쉽게 실행계획을 확인할 수 있는데요, 아래 명령어를 SQL*PLUS 에서 사용하면 쿼리를 수행했을 때 쿼리 결과 하단에 실행계획이 보이는 것을 확인하실 수 아래 사진에서 함께 확인하실 수 있습니다.
set autotrace on exp
사실 이 기능보다 중요한건 실행계획을 읽는 방법입니다. 이건 글로 설명하는 것보다 실제 사진으로 한번 같이 보는게 더 편하실 겁니다. 이 쿼리는 우선 D_LOC_I 라는 인덱스를 스캔해 DEPARTMENTS 테이블에 접근했고, EMPLOYEES 테이블을 풀스캔 방식으로 접근했습니다. 그리고 이 두 테이블을 NL 방식으로 조인한 결과를 가져옵니다.

어느 정도 읽는 방법이 파악이 되시나요? 들여쓰기를 기준으로 가장 안쪽부터 읽고, 같은 수준에서서는 위에서 아래로 읽는다고 생각하면 되는데, 다음과 같이 정리할 수 있겠습니다.
💡 실행계획(Execution Plan) 보는 방법
1. 들여쓰기를 기준으로 같은 depth 는 box 로 묶어준다.
2. 동일한 depth 의 box 에선 위 ➡️ 아래 box 순서로 읽는다. (예. 2 → 4)
3. 같은 Box 내에선 안쪽의 작은 box부터 읽는다. (예. 3 → 2)
4. 쿼리 힌트(Oracle)
4-1. 힌트의 정의
사용자가 작성한 쿼리에 대해 옵티마이저가 항상 최적의 실행계획을 생성하지는 않습니다. 따라서 개발자가 옵티마이저에게 특정한 실행계획을 유도해야할 때도 존해하는데요, 힌트란 이와 같이 옵티마이저가 쿼리에 대한 최적의 실행계획을 생성하는 데 있어 도움을 주는 키워드라고 할 수 있습니다. 다만, 힌트를 사용하기 위해선 개발자가 액세스 되는 데이터에 대해서 옵티마이저보다 더 잘 이해하고 있어야 한다는 전제가 있으니 무분별한 힌트사용은 지양하는 것이 좋습니다.
4-2. 힌트 사용 시 유의사항
힌트는 쿼리 결과에 영향을 주지 않고, 오타가 포함되는 등 잘못 사용된 힌트는 옵티마이저에 의해 무시된다는 특징이 있습니다. 뿐만 아니라 옵티마이저가 적용 가능하다고 판단한 경우에만 채택되고, 강제 적용되지는 않는다는 점도 유의해야 합니다. 이 외에 구체적인 사용법은 아래 내용을 참고해주세요.
(1) SELECT 바로 뒤에 위치해야 하며, 위치가 다르면 무시됩니다.
-- 올바른 힌트 사용 --
select /*+ index(employee emp_sal_idx) */ ename, sal
from employee
-- 틀린 사용 --
select ename, sal /*+ index(employee emp_sal_idx) */
from employee(2) 테이블 별칭(alias)을 사용할 경우 힌트에도 별칭을 사용해야 합니다.
-- 올바른 힌트 사용 --
select /*+ index(e emp_sal_idx) */ ename, sal
from employee e
-- 틀린 사용 --
select /*+ index(employee emp_sal_idx) */ ename, sal
from employee e(3) 여러 힌트 적용 시 하나의 구문 안에 다 포함해야 합니다.
-- 올바른 힌트 사용 --
select /*+ use_nl(e d) leading(e d) */ ename, sal
from employee e, department d
-- 틀린 사용 --
select /*+ use_nl(e d) */ /*+ leading(e d) */ ename, sal
from employee e, department d(4) 서브쿼리 사용 시 힌트 사용이 가능합니다.
select /*+ 힌트 */ ename, sal
from employee
where sal > (select /*+ 힌트 */ sal
from ...
where ...
5. 마무리
이번 포스팅을 통해 SQL의 처리단계부터 실행계획과 힌트 등 튜닝의 기본이 되는 정보들을 정리해보았습니다. 다음 포스팅에서는 튜닝의 가장 중요한 포인트 중 하나인 인덱스에 대해 다뤄보도록 하겠습니다.
reference
https://docs.oracle.com/en/database/oracle/oracle-database/21/dbiad/index.html
'Web Development > Database' 카테고리의 다른 글
| [DB] 하드파싱(Hard parsing)과 소프트파싱(Soft parsing) 그리고 라이브러리 캐시(Library cache) (0) | 2022.08.21 |
|---|

댓글